
With the rise of modern AI systems, you often hear phrases like, “The text is converted into an embedding…” – especially when working with large language models (LLMs). However, embeddings are not limited to text; they are vector representations for all types of data.
Deep learning has evolved significantly in recent years, particularly with the training of large models on large datasets. These models generate versatile embeddings that prove useful across many domains. Since most developers lack the resources to train their own models, they use pre-trained ones.
Many AI systems follow this basic workflow:
Input → API (to large deep model) → Embeddings → Embeddings are processed → Output
In this blog post, we take a closer look at this fundamental component of AI systems.
What are embeddings?
Simply put, an embedding is a kind of digital summary: a sequence of numbers that captures the characteristics of an object, whether it is text, an image, or audio. Similar objects have embeddings that are close to each other in the vector space.
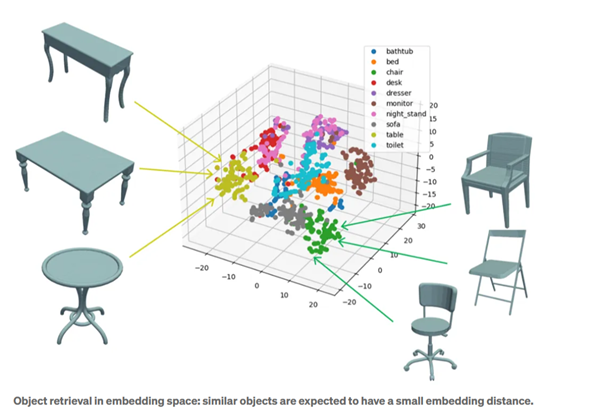
Technically speaking, embeddings are vector representations of data. They are based on a mapping (embedder, encoder) that functions like a translator. Modern embeddings are often created using deep neural networks, which reduce complex data to a lower dimension. However, some information is lost through compression, meaning that the original input cannot always be exactly reconstructed from an embedding.
How do embeddings work?
Embeddings are not a new invention, but deep learning has significantly improved them. Users generate them either manually or automatically through machine learning. Early methods like Bag-of-Words or One-Hot Encoding are simple approaches that represent words by counting their occurrences or using binary vectors.
Today, neural networks handle this process. Models like Word2Vec or GloVe automatically learn the meaning of and relationships between words. In image processing, deep learning models identify key points and extract features.
Why are embeddings useful?
Because almost any type of data can be represented with embeddings – text, images, audio, videos, graphs, and more. In a lower-dimensional vector space, tasks such as similarity search or classification are easier to solve.
For example, if you want to determine which word in a sentence does not fit with the others, embeddings allow you to represent the words as vectors, compare them, and identify the “outliers”. Additionally, embeddings enable connections between different formats. For example, a text query also finds images and videos.
In many cases, you do not need to create embeddings from scratch. There are numerous pre-trained models available, from ChatGPT to image models like ResNet. These can be adapted accordingly for specialized domains or tasks.
Small numbers, big impact
Embeddings have become one of the buzzwords in AI development. The idea is simple: transforming complex data into compact vectors that make it easier to solve tasks like detecting differences and similarities. Developers can choose between pre-trained embeddings or training their own models. Embeddings also enable different modalities (text, images, videos, audio, etc.) to be represented within the same vector space, making them an essential tool in AI.
For a more detailed look at this topic, check out the CONTACT Research Blog.

