
Companies face the challenge of designing sustainable products and processes and reducing emissions across their entire lifecycle. The Product Carbon Footprint (PCF) captures all greenhouse gas emissions generated throughout a product’s lifecycle. While internal emissions data is often available, companies need to track and consolidate data across a product’s entire supply chain to determine the PCF. Requesting and collecting this information individually from every single supplier is hardly feasible. This is where sovereign data ecosystems like Catena-X and Manufacturing-X come into play. They enable easier, more controlled data exchange across company boundaries.
External data in PCF calculation
Product Lifecycle Management (PLM) systems already manage much of the data needed to determine the PCF. They contain information on products, variants, and bills of materials. However, many emissions originate earlier in the upstream value chain, for instance, during raw material extraction or through production and transportation processes. Requesting and maintaining this data is complex and is currently done using document-based templates, Excel spreadsheets, or specialized web portals. Data is shared on demand.
For suppliers, the approach with customer-specific portals and templates simply doesn’t scale. Requested data fields lack standardization, while input data, formats, and calculation methods often don’t align. This creates immense overhead for everyone involved: data is manually compiled, entered, and verified, increasing the risk of transfer errors.
Data ecosystems as an alternative
Data ecosystems such as Gaia-X and Catena-X counteract these data silos and simplify sharing across the entire supply chain. Instead of individually requesting necessary data and uploading it to various platforms for each customer, companies provide it in standardized data formats. If a participant in the ecosystem needs this data, they simply access it through defined protocols. Control remains with the data provider. Each participant decides for themselves which data they make available, with whom they share it, and for what purposes it can be used.
The foundation is a connector based on Eclipse Dataspace Components (EDC). Each participant uses their EDC connector to manage the data and conditions under which they wish to participate in the ecosystem. The connector compiles these into a searchable catalog. If another company wants to access the data, the two EDCs automatically negotiate the terms and conditions governing the data exchange. Only with such a legally binding agreement does the other participant gain access to the data. This way, every participant retains full control over their data.
PCF calculation within data ecosystems
PLM systems are the ideal starting point for PCF calculations. Bills of materials and work plans form the basis for capturing internal emissions. Data ecosystems now enable companies to integrate data from external partners and suppliers into their calculation. For purchased parts, not only suppliers but also their digital identities are managed within the data space. This makes it possible to search for and import PCF values for external items directly from the supplier’s EDC.
Once a product’s PCF calculation is complete, the results can be made available within the data ecosystem for further use along the value chain. Each company thus individually determines with whom and under what conditions it shares the data. The relevant data set is then available in its own EDC catalog, without the need for Excel spreadsheets and web portals.
Why PLM systems are the natural integration point
This entire workflow must take place where product data is already managed: PLM systems manage bills of materials, supplier relationships, and engineering workflows. They are the single source of truth for product information throughout the lifecycle.
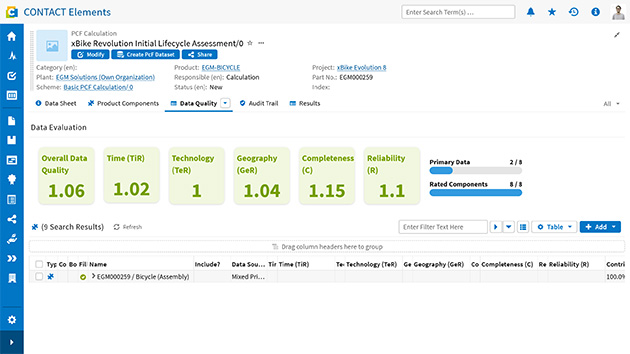
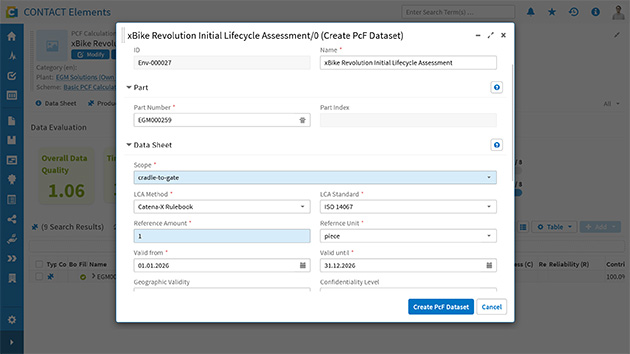
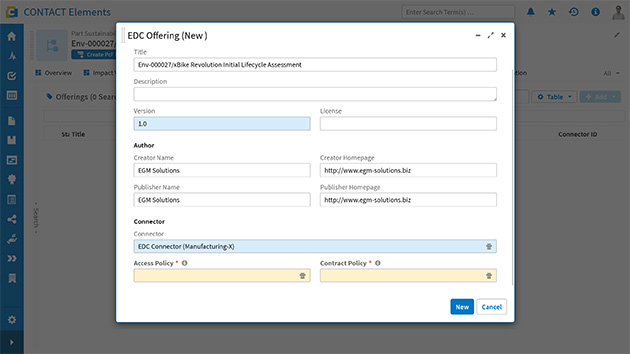
Fully exploiting the potential of data ecosystems requires PLM systems with open standard interfaces. Engineering workflows now also govern how internal and external PCF data is integrated. The supplier database now includes identities within the data space, and audit trails capture external data exchanges in addition to internal changes.
Today, value creation largely stems from the ability to quickly and reliably exchange product data across the supply chain. Only deep integration between internal PLM systems and external data ecosystems can generate the necessary efficiency and build trust, both internally and externally.

