
In der datengetriebenen Welt von heute ist der sichere und effiziente Austausch von Daten ein entscheidender Wettbewerbsvorteil. Unternehmen müssen in der Lage sein, Daten aus verschiedenen Quellen zu integrieren und gemeinsam zu nutzen, ohne dabei die Kontrolle über ihre eigenen Daten zu verlieren. Hier kommt Gaia-X ins Spiel: ein Leuchtturmprojekt der Europäischen Union, das eine sichere, vertrauenswürdige und souveräne Dateninfrastruktur für Europa schafft.
In unserer Research Area Daten- & Service-Ökosysteme bei CONTACT arbeiten wir daran, dass die Vision von Gaia-X Realität wird. Ein Schlüssel dazu ist die nahtlose Verbindung von Datenmanagementsystemen zu Gaia-X-basierten Datenräumen.
Was ist Gaia-X und warum ist es wichtig?
In einer zunehmend globalisierten und datengetriebenen Welt ist es für Unternehmen entscheidend, die Kontrolle über ihre Daten zu behalten und gleichzeitig von den Vorteilen des Datenaustauschs zu profitieren. Gaia-X bietet hierfür den Rahmen: Das Kernkonzept für eine föderierte Dateninfrastruktur bietet Plattformanbietern, Cloud-Diensten und Datenhaltern die Möglichkeit, sicher und rechtskonform miteinander zu kommunizieren und Daten auszutauschen.
Gaia-X zielt nicht darauf ab, bestehende Dateninfrastrukturen zu ersetzen, sondern diese zu verbinden und ein offenes, interoperables Ökosystem zu schaffen. Um die Tragweite dieser Veränderung zu verstehen, hilft es, die Unterschiede zwischen Datenplattformen und Datenökosystemen zu betrachten:
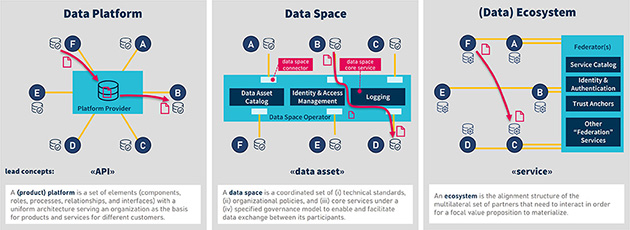
Datenplattformen basieren in der Regel auf einem zentralisierten Modell. Daten werden kopiert und auf die Plattform hochgeladen, sodass andere Parteien sie herunterladen und nutzen können. Das Problem dabei: Überall existieren Kopien der Daten, und alle Teilnehmer*innen müssen dem Plattformbetreiber vertrauen, dass er die Daten sicher und korrekt verwaltet.
Im Gegensatz zur zentralisierten Datenplattform verschiebt sich in einem Daten- und Service-Ökosystem die Rolle des Betreibers hin zu einem Föderator. Dieser bietet Federation Services an, mit denen sich Teilnehmende gegenseitig finden, vertrauen und Daten direkt austauschen können, ohne dass eine zentrale Instanz die Daten verwaltet oder kontrolliert.
Die Kernpfeiler von Gaia-X bilden dabei die Grundlage für ein vertrauenswürdiges und zukunftsfähiges Datenökosystem:
- Vertrauen & Transparenz: Gaia-X etabliert klare Regeln für Daten-Governance, Sicherheit und Datenschutz. Das System ist von Grund auf DSGVO-konform konzipiert, gewährleistet so die Privatsphäre der Nutzer und die Sicherheit ihrer Daten.
- Interoperabilität: Durch die Einhaltung offener Standards und Schnittstellen bewegen sich Daten und Dienste frei zwischen konformen Anbietern.
- Portabilität: Unternehmen können ihre Daten und Anwendungen problemlos zwischen verschiedenen Gaia-X-konformen Anbietern verschieben, ohne sich an einen bestimmten Anbieter zu binden. Dies fördert den Wettbewerb und gibt Unternehmen die Flexibilität, die für ihre Geschäftsanforderungen am besten geeigneten Lösungen auszuwählen.
- Souveränität: Die Datenhoheit bleibt jederzeit beim Eigentümer. Unternehmen behalten die Kontrolle über den Zugriff und die Nutzung ihrer Daten, unter strikter Einhaltung europäischer Gesetze und Werte.
Gaia-X ist somit ein wichtiger Schritt hin zu einer digitalen Souveränität Europas und bietet Unternehmen die Möglichkeit, Innovationen voranzutreiben, neue Geschäftsmodelle zu entwickeln und gleichzeitig die Kontrolle über ihre wertvollen Daten zu behalten.
Anforderungen an die Teilnahme am Gaia-X-Ökosystem
Die Teilnahme am Gaia-X-Ökosystem eröffnet Unternehmen zahlreiche Möglichkeiten, erfordert jedoch auch die Erfüllung bestimmter Anforderungen.
- Compliance mit dem Gaia-X Trust Framework: Dies beinhaltet die Einhaltung von Regeln und Richtlinien für Datengovernance, Datensicherheit, Datenschutz und Interoperabilität.
- Betrieb eigener Infrastruktur: In der Regel ist der Betrieb einer eigenen Infrastruktur notwendig, um die volle Datensouveränität zu gewährleisten. Das kann beispielsweise den Betrieb eines Objektspeichers (wie S3), einer Self-Sovereign Identity (SSI)-Lösung oder anderer erforderlicher Services umfassen.
- Implementierung von Sicherheitsmaßnahmen: Unternehmen müssen angemessene Sicherheitsmaßnahmen implementieren, um ihre Daten und Systeme vor unbefugtem Zugriff, Verlust oder Beschädigung zu schützen.
- Einhaltung von Standards: Gaia-X setzt auf offene Standards und Schnittstellen für die Interoperabilität zwischen verschiedenen Systemen und Plattformen.
Fazit
Gaia-X ist die strategische Antwort Europas auf die Herausforderungen der digitalen Ära. Indem ein vertrauenswürdiges, interoperables und souveränes Datenökosystem geschaffen wird, ermöglicht Gaia-X Unternehmen und Organisationen ihre Daten nicht nur sicher zu speichern, sondern auch kontrolliert zu teilen und intelligent zu nutzen.
Dies fördert nicht nur Innovationen und neue Geschäftsmodelle über Branchengrenzen hinweg, sondern sichert auch eine faire Wettbewerbslandschaft, in der auch kleinere Akteure von den Potenzialen datengetriebener Wertschöpfung profitieren können. Nutzer und Unternehmen erhalten die Kontrolle über ihre Daten zurück, was die Grundlage für Transparenz und Vertrauen im digitalen Raum bildet.
Erfahren Sie im nächsten Blogartikel, wie wir mit der Anbindung von CONTACT Elements an Pontus-X den Grundstein für den föderierten Datenaustausch legen.

