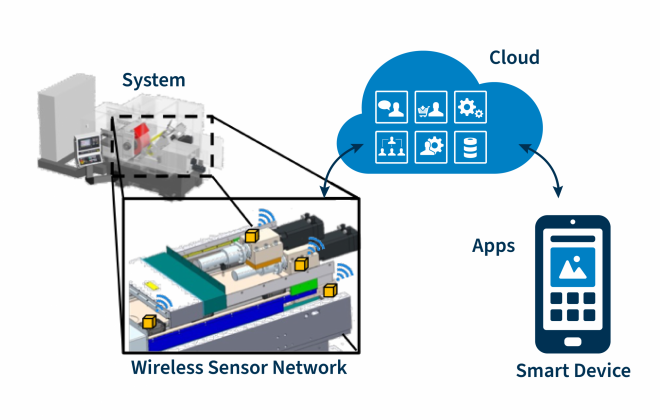
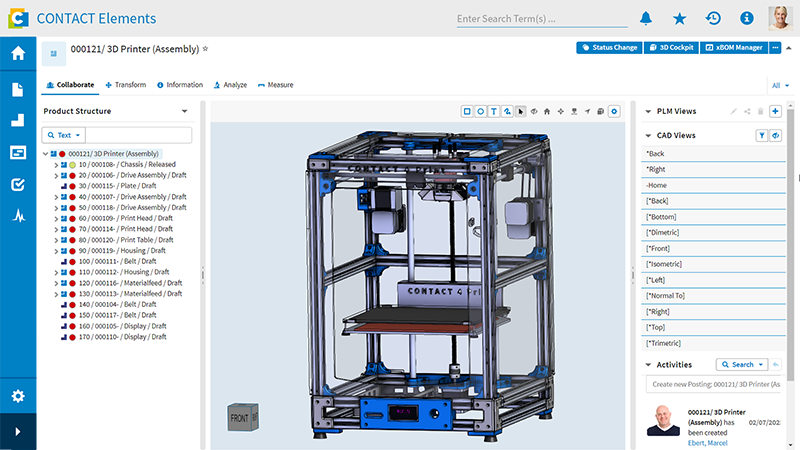
In der heutigen datengetriebenen Welt sind Digitale Zwillinge unverzichtbar, um Prozesse zu optimieren und die Effizienz zu steigern. Dennoch ist der Einstieg für viele Unternehmen oft nicht leicht, insbesondere wenn spezialisierte Ressourcen fehlen. Hier kommt Power Apps ins Spiel: Ein rein visuelles Entwicklungstool für die Erstellung von Digital Twin-Anwendungen, das keine tiefgehenden Programmierkenntnisse erfordert.
Power Apps als einfache und effektive Basis
Power Apps basiert auf der JavaScript-Bibliothek Blockly, die eine visuelle Programmieroberfläche bereitstellt. Nutzer*innen können mit grafischen Blöcken Programmierkonzepte wie Variablen, Schleifen oder logische Ausdrücke umsetzen – ohne zu Coden. Diese intuitive Herangehensweise ermöglicht es, Digitale Zwillinge mit wenigen Klicks zu erstellen.
CONTACT Elements: Die Plattform für digitale Zwillinge
Power Apps ist Bestandteil der CONTACT Elements-Plattform , die alle Daten und Prozesse von der ersten Idee bis zum Recycling eines Produkts entlang des Digital Thread (digitaler Faden) durchgängig verbindet und die digitale Transformation beschleunigt. Nutzer*innen können Digitale Zwillinge von Produkten, Systemen oder Prozessen erstellen, verwalten und optimieren – individuell und ohne aufwendige Backend-Programmierung.
Einfache Integration von Simulationen, Datenanalysen oder KI
Mit Power Apps lassen sich automatisierte Schnittstellen zu bestehenden Systemen und Datenquellen schneller umsetzen, was den Datenfluss zum Digitalen Zwilling deutlich erleichtert. Python Skripte ergänzen dabei komplexere Algorithmen für Simulationen oder maschinelles Lernen (ML). Bibliotheken wie TensorFlow oder Pandas ermöglichen Zustände von Maschinen und Anlagen präzise vorherzusagen. Simulationen bieten darauf aufbauend eine gezielte Analyse verschiedener Szenarien sowie deren Auswirkungen auf Systeme.
Ergebnisse wie KPIs oder Zeitreihen lassen sich in der Elements-Plattform in Geschäftsprozesse einbinden – ideal für Unternehmen aus der Fertigungs-, Gesundheits- oder Energiebranche, die auf genaue Prognosen angewiesen sind.
Anwendungen flexibel anpassen
Die intuitive Benutzeroberfläche von Power Apps erlaubt es, mit nur wenigen Klicks maßgeschneiderte Anwendungen zu entwickeln und an spezifische Anforderungen anzupassen. Daten aus Dokumenten, Sensoren oder Simulationen können verarbeitet, berechnet und direkt im Dashboard des digitalen Zwillings visualisiert werden.
Keine IT-Hürden und komplexe Freigaben mehr
Power Apps benötigt keine komplexen IT-Tools oder Freigabeprozesse. Nutzer*innen können Anwendungen direkt auf der CONTACT Elements-Plattform erstellen, anpassen und freigeben. Dadurch können sie schnell auf neue Anforderungen reagieren.
Fazit
Die visuelle Programmierung mit innovativen Lösungen wie Power Apps auf der CONTACT Elements-Plattform erleichtert es, Anwendungen für digitale Zwillinge zu erstellen und zu automatisieren. Ohne aufwendige IT-Infrastruktur werden digitale Zwillinge so für Unternehmen jeder Größe zugänglich.
Vorteile auf einen Blick:
- Schnelle Entwicklung: Iterative Anpassungen und User-Feedback in Echtzeit.
- Optimierung durch Simulation: Erkenntnisse aus Analysen direkt in Modelle einfließen lassen.
- Integration in Geschäftsprozesse: Ergebnisse nahtlos in Workflows oder Servicefälle einbinden.
Mit der einfachen und flexiblen Erstellung digitaler Zwillinge eröffnen sich Unternehmen neue Möglichkeiten, Effizienz zu steigern und Innovationen voranzutreiben.