Künstliche Intelligenz (KI) ist im Engineering nicht mehr wegzudenken. Anwendungen wie ChatGPT oder GitHub Copilot erhöhen die Effizienz schon heute in vielen Bereichen der Produktentwicklung. Während Ihr Unternehmen diese Werkzeuge einfach und schnell einsetzen kann, ist die Implementierung industrieller AI-Lösungen aufgrund der spezifischen Fragen und komplexen Prozesse deutlich anspruchsvoller. Zumal es häufig an der benötigten Datenqualität, -menge und -infrastruktur mangelt. Hier kommen Systeme für Product Lifecycle Management (PLM) ins Spiel.
PLM-Lösungen bieten nicht nur eine Plattform zur Verwaltung von Produktdaten. Sie liefern auch eine wichtige Schnittstelle, mit der sich KI-gestützte Technologien in verschiedenen Phasen des Engineerings implementieren lassen.
Industrielle KI implementieren
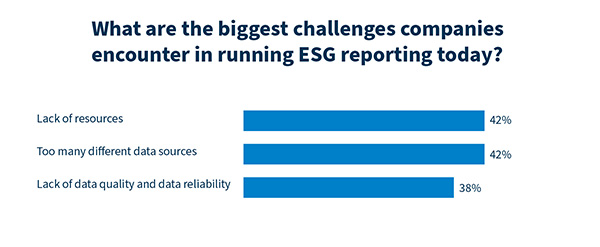
Wenn Sie AI nutzbringend in industrielle Prozesse integrieren wollen, stehen Sie vor mehreren Herausforderungen. Eine der größten ist, geeignete KI-Modelle zu trainieren und Daten in ausreichender Qualität bereitzustellen.
Fertige Anwendungen wie ChatGPT oder Dall-E sind für generische Anwendungszwecke wie Textarbeit oder Bilderstellung sofort nutzbar. Solche Anwendungen und Modelle fehlen für komplexe industrielle Fragestellungen. Öffentlich zugängliche Datensätze sind selten auf industrielle Anforderungen zugeschnitten. Daher müssen Unternehmen KI-Modelle gezielt anpassen und firmenspezifische Datensätze und Modelle erstellen.
Darüber hinaus müssen Sie komplexe Anforderungen an das Deployment von KI-Modellen berücksichtigen. Dies betrifft insbesondere
- die Integration in bestehende Systeme,
- die Zugriffssicherheit und Autorisierung im Umgang mit den dahinterliegenden Daten und
- die Sicherstellung von Zuverlässigkeit und Performance.
Wie hilft PLM-Software hier weiter?
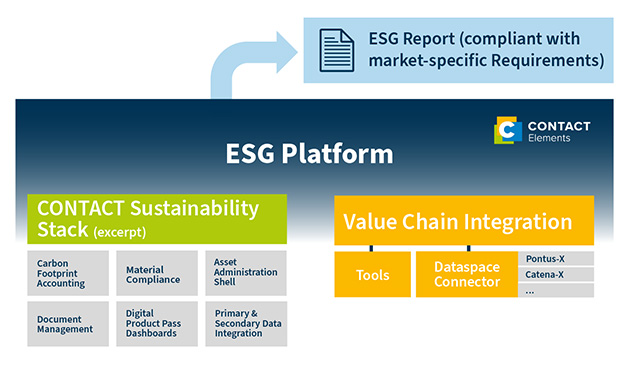
PLM-Systeme bieten die nötige Infrastruktur, um Daten zu sammeln, zu strukturieren und aufzubereiten. Sie ermöglichen es, KI-Modelle in bestehende Prozesse zu integrieren, und bieten eine zentrale Plattform, um KI-Lösungen über den gesamten Produktlebenszyklus zu managen. Dies umfasst die Sicherstellung der Datenqualität, die Versionierung und die Verwaltung der generierten Ergebnisse.
Mit der Verbindung von KI-Tools und PLM-Systemen stellen Sie eine konsistent strukturierte Nutzung Ihrer Daten sicher. So entsteht die Grundlage für erfolgreiche KI-Anwendungen.
Eine zweite große Herausforderung ist die Komplexität der KI-Implementierung. Das reicht von der Auswahl geeigneter Modelle und Algorithmen bis hin zur Anpassung dieser Modelle an Ihre spezifischen Anforderungen.
Um AI erfolgreich zu integrieren, sind die Expertise der Ingenieur*innen und Datenwissenschaftler*innen sowie die Zusammenarbeit zwischen Abteilungen wie IT, Engineering und Datenwissenschaft entscheidend. PLM-Systeme unterstützen den Prozess als Plattform für nahtlose Zusammenarbeit und Kommunikation zwischen Ihren Teams.
PLM-Systeme als Wegbereiter für KI
PLM-Software mit tiefer Integrationsfähigkeit erzeugt die Voraussetzungen, um KI in bestehenden Engineering-Prozessen einzusetzen. Als zentrale Datendrehscheiben ermöglichen sie es, auf Daten aus verschiedenen Quellen im Produktlebenszyklus zuzugreifen.
Die konsolidierte Datenbasis des PLM-Systems ebnet den Weg für generative KI-Technologien (GenAI). Dabei handelt es sich um KI-Lösungen, die selbstständig neue, kreative Inhalte wie Texte oder Bilder erschaffen. Dadurch eröffnen sich Unternehmen völlig neue Möglichkeiten, zum Beispiel im Design und in der Produktentwicklung.
Indem PLM-Systeme die Integration von KI-gestützten Design-Tools erleichtern, sorgen sie für eine effiziente Verwaltung und Versionierung von KI-generierten Designs. Sie können beispielsweise Varianten von CAD-Modellen automatisiert erstellen. Bewährt haben sich auch Designoptimierungen, die auf Basis von Simulationsergebnissen generiert werden.
Wesentlich ist außerdem, KI-Lösungen mit bestehenden Datenstrukturen zu verknüpfen. Durch die Integration von KI in PLM-Systeme verbinden Sie KI-gesteuerte Designwerkzeuge direkt mit Ihren Produktdaten. Dies beschleunigt nicht nur den gesamten Entwicklungsprozess. Ihr Unternehmen gestaltet die Wiederverwendung von Komponenten effizienter, verbessert die Zusammenarbeit zwischen Teams und optimiert die Produktentwicklung kontinuierlich.
Ein weiterer Vorteil: PLM-Systeme speichern KI-generierte Erkenntnisse und Optimierungen zentral. Das macht sie für zukünftige Projekte nutzbar. Dadurch können Sie Ihre Innovationsfähigkeit erheblich steigern.
PLM-Systeme sind weit mehr als nur Datenverwaltungssysteme. Es sind zentrale Plattformen für den Einsatz KI-gestützter Assistenz-Systeme.
Solche Systeme helfen zum Beispiel bei Designentscheidungen. Sie analysieren Daten aus ähnlichen Projekten und liefern konkrete Verbesserungsvorschläge. Darüber hinaus führen sie Simulationen durch und stellen die Ergebnisse in einer Form dar, die für Ingenieur*innen verständlich ist. Das Ergebnis: bessere Entscheidungen, kürzere Entwicklungszeiten.
KI-Anwendungen im Engineering
Durch das Zusammenspiel von GenAI und PLM-System integrieren Sie KI-basierte Designprozesse nahtlos in bestehende Workflows. Daraus ergeben sich vielseitige Use Cases:
Automatisierte Designvarianten
Künstliche Intelligenz erstellt neue Designvarianten auf Basis bestehender CAD-Daten und optimiert diese automatisch auf Parameter wie Kosten, Materialeinsatz oder Produktionsmöglichkeiten. Ingenieur*innen gewinnen mehr Zeit für kreative Designaufgaben.
Simulationsgestützte Optimierungen
Mit Simulationstools, die GenAI-Algorithmen nutzen, verbessern Sie Designvorschläge kontinuierlich und passen sie auf Basis von Simulationsergebnissen iterativ an. So treffen Sie die besten Designentscheidungen auf Basis umfassender Datenanalysen. Dies reduziert die Anzahl physischer Prototypen und spart Zeit und Kosten.
Optimierung der Produktentwicklung
KI passt Designs dynamisch an neue Anforderungen an – während der laufenden Entwicklung. In Verbindung mit dem PLM-System können Sie schneller auf Änderungen reagieren und die Produktentwicklung ohne Verzögerungen anpassen. Dies bietet insbesondere dem Maschinen- und Anlagenbau große Vorteile.
Zeitreihenvorhersagen
GenAI analysiert Zeitreihendaten und sagt zukünftige Entwicklungen voraus. Auf Grundlage historischer Daten und anderer betrieblicher Informationen helfen PLM-Systeme in Kombination mit KI, Trends frühzeitig zu erkennen und fundierte Entscheidungen zu treffen.
Datenmanagement und Deployment
Die Integration von KI in die Produktentwicklung ist nicht nur technisch, sondern auch organisatorisch komplex. Damit KI seine Wirkung erzielt, braucht es ein geeignetes Datenmanagement. Auch hier sind PLM-Systeme eine große Hilfe.
Mit einer PLM-Lösung verwalten Sie Daten konsistent und strukturiert – von der Erfassung über die Speicherung bis zur Bereitstellung für KI-Modelle. Dabei müssen Unternehmen Datenschutz, -sicherheit und -verfügbarkeit gewährleisten.
Neben der Datenverarbeitung ist auch das Deployment – die Bereitstellung in der produktiven Umgebung – entscheidend. Um KI-Lösungen in bestehende IT-Infrastrukturen zu integrieren, müssen Ihre IT- und Engineering-Teams eng zusammenarbeiten. PLM-Systeme ermöglichen es, KI-Anwendungen sicher und leistungsstark zu integrieren und sie für die Anwender*innen im Tagesgeschäft einfach zugänglich zu machen.
Damit müssen PLM-Systeme sowohl die Entwicklung und Integration von KI-Modellen unterstützen als auch deren Betrieb und Wartung im laufenden Geschäft sicherstellen.
Ein weiterer wichtiger Aspekt ist die kontinuierliche Verbesserung von KI-Modellen. Hier unterstützen PLM-Systeme als Plattform für das Monitoring und die Aktualisierung. Auf Basis von gesammelten Betriebsdaten lassen sich KI-Modelle kontinuierlich verbessern und an Veränderungen anpassen. Dies stellt ihren Nutzen langfristig sicher.
Welche Trends zeichnen sich ab?
PLM-Systeme dienen künftig zunehmend als zentrale Plattformen für die Verwaltung und Integration von KI-Lösungen. Eine immer größere Bedeutung gewinnt die KI-gestützte Automatisierung, denn die Fähigkeiten, aus Daten zu lernen und komplexe Zusammenhänge zu erkennen, wird stetig verbessert.
Ein weiterer Trend ist die immer stärkere Integration von KI in die Zusammenarbeit zwischen Abteilungen und Unternehmen. PLM-Systeme entwickeln sich dabei zu Plattformen, die sowohl interne Prozesse unterstützen als auch eine vernetzte Zusammenarbeit über Unternehmensgrenzen hinweg ermöglichen. Das Ergebnis sind effizientere Lieferketten und beschleunigte Innovationen.
Auch erklärbare und transparente AI-Modelle gewinnen zunehmend an Bedeutung. Sie stärken das Vertrauen in KI-Lösungen und erhöhen deren Akzeptanz in sicherheitskritischen Bereichen des Engineerings.
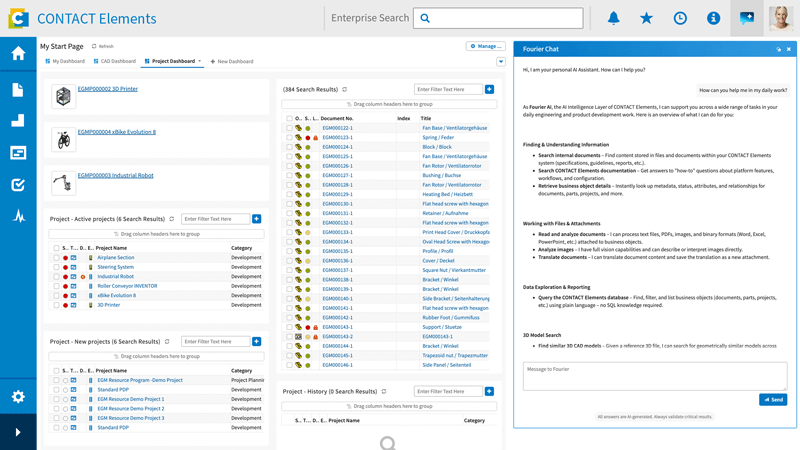
Erfolgsfaktoren für KI im Engineering
Datenverfügbarkeit und -qualität
Die Grundlage für den Erfolg von KI-Anwendungen bilden hochwertige Daten (und deren Verfügbarkeit). PLM-Systeme stellen durch eine konsistente Datenerfassung und -verwaltung sicher, dass die benötigten Daten in der erforderlichen Qualität zur Verfügung stehen. So können Modelle auf einer soliden Datenbasis trainieren und präzise, verlässliche Ergebnisse liefern.
Nahtlose Prozessintegration
Um den vollen Mehrwert von KI-Technologien auszuschöpfen, müssen Unternehmen diese in bestehende Workflows einbinden. PLM-Systeme integrieren KI-gestützte Anwendungen in bestehende Prozesse und vereinfachen deren Nutzung. Dadurch lassen sich KI-Lösungen ohne große Anpassungen in bestehende Systeme einführen und schneller in Betrieb nehmen.
Schulungen und Change Management
Unternehmen müssen ihre Mitarbeiter*innen gezielt auf die Nutzung von KI-Tools vorbereiten. Dafür sind technische Schulungen notwendig, in denen auch ein Verständnis für den Einsatz im jeweiligen Arbeitskontext vermittelt wird. Durchdachtes Change Management fördert die Akzeptanz und involviert alle Mitarbeiter*innen aktiv in den Veränderungsprozess.
Unterstützung durch das Management
Die erfolgreiche Einführung von KI im Engineering gelingt nur, wenn das Management entsprechende Initiativen unterstützt. Die Kommunikation klarer Ziele und Strategien für die Transformation ist ebenso wichtig wie die Bereitstellung nötiger Ressourcen. Zugleich muss das Management eine Kultur des Wandels fördern.
Zusammenfassung
Die Integration von KI revolutioniert das Engineering. PLM-Systeme nehmen dabei als zentraler Dreh- und Angelpunkt der Daten eine Schlüsselrolle ein. Sie schaffen die notwendige Infrastruktur, um KI-Anwendungen in bestehende Prozesse zu integrieren und effizient zu nutzen.
Kritische Erfolgsfaktoren sind die sinnvolle Nutzung von Daten, die Integration von KI-Modellen in die bestehende IT-Landschaft sowie die Einbindung der Mitarbeiter*innen. Nur wer diese Herausforderungen gezielt angeht, gestaltet die KI-Transformation im Engineering nachhaltig.
Ratsam ist ein strategisches Vorgehen. Ihr Unternehmen sollte Technologie und Menschen gleichermaßen in den Fokus rücken. So schöpfen Sie das volle Potenzial von KI im Engineering nachhaltig aus.