
Die Entwicklung der Sprachmodelle im Bereich NLP (Natural Language Processing) hat vor allem seit 2019 zu gewaltigen Sprüngen in der Genauigkeit dieser Modelle für bestimmte Aufgaben geführt, aber auch in der Anzahl und dem Umfang der Fähigkeiten an sich. Als Beispiel seien die mit viel Medienrummel von OpenAI veröffentlichen Sprachmodelle GPT-2 und GPT-3 genannt, die mittlerweile für den kommerziellen Einsatz verfügbar sind und sowohl in Art, Umfang und Genauigkeit erstaunliche Fähigkeiten haben, auf die ich in einem anderen Blog-Post eingehen möchte. Dies wurde im Fall von GPT-3 durch Training mittels eines Modells mit 750 Milliarden Parametern auf einem Datensatz von 570 GB erreicht. Das sind Werte, die einem die Sprache verschlagen.
Je größer die Modelle, je höher die Kosten
Gigantisch sind aber auch die Kosten, die das Training dieser Modelle verschlingt: Setzt man nur die angegebenen Compute-Kosten 1 für einen kompletten Trainingslauf an, kommt man auf eine Größenordnung von 10 Millionen USD für das Training von GPT-3 2, 3. Hinzu kommen weitere Kosten für Vorversuche, Storage, Commodity-Kosten für die Bereitstellung etc., die in ähnlicher Größenordnung liegen dürften. In den vergangenen Jahren hat sich der Trend, immer größere Modelle zu bauen, verstetigt und jedes Jahr kommt ungefähr eine Größenordnung hinzu, d.h. die Modelle sind 10x größer als im Jahr davor.
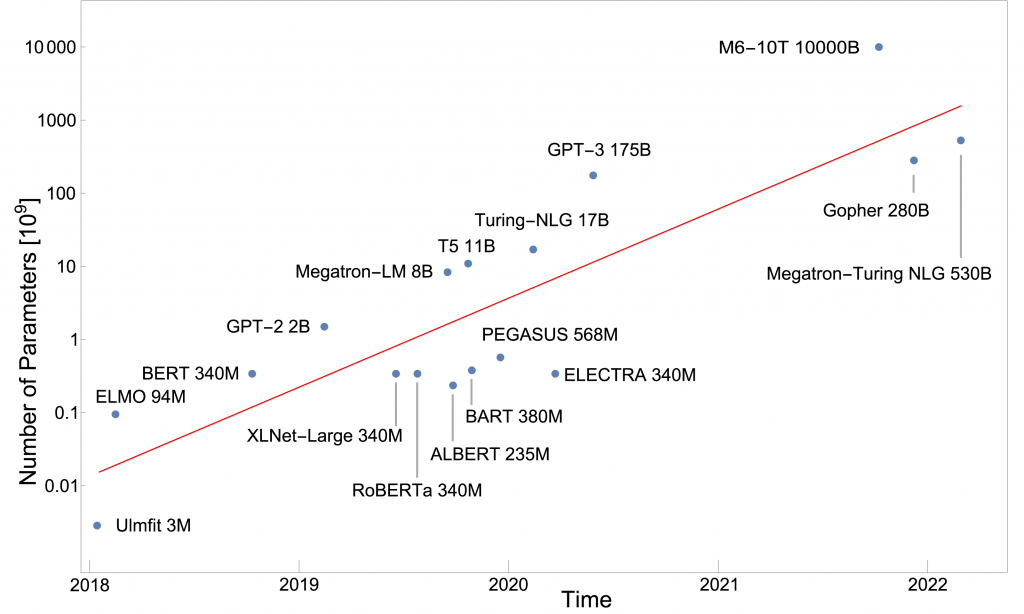
Das nächste Modell von OpenAI GPT-4 soll ca. 100 Billionen Parameter haben (100 x 1012 ). Zum Vergleich: Das menschliche Gehirn hat ungefähr 100 Milliarden Neuronen (100 x 109) also 1000 mal weniger. Die theoretische Grundlage für diesen Gigantismus liefern Studien, die ein klares Skalenverhalten zwischen Größe des Modells und Performance belegen 4. Danach sinkt der sogenannte Verlust – ein Maß für die Fehlerhaftigkeit der Vorhersagen der Modelle – um 1, wenn das Modell 10mal größer wird. Das funktioniert aber nur wenn Rechenleistung und Trainingsmenge ebenfalls nach oben skaliert werden.
Neben den ungeheuren Mengen Energie, die das Berechnen dieser Modelle verschlingt und dem damit einhergehenden CO2-Footprint, der ein Besorgnis erregendes Ausmaß annimmt, ergeben sich direkte wirtschaftliche Folgen: Offenbar können nicht nur kleinere Unternehmen die Kosten für das Training solcher Modelle nicht stemmen, auch größere Konzerne dürften vor Kosten von 10 Mio. USD bzw. in Zukunft 100 Mio. USD oder mehr zurückschrecken. Ganz abgesehen von der notwendigen Infrastruktur und Personalausstattung für ein solches Unterfangen.
Monopolstellung der großen Player
Das hat direkte Auswirkungen auf die Verfügbarkeit: Während die kleineren Modelle bis Ende 2019 mittlerweile Open Source sind und über spezialisierte Provider frei zugreifbar, gilt das für die großen Modelle ab ca. Ende 2020 (dem Auftauchen von GPT-2) nicht mehr. OpenAI bietet zum Beispiel eine kommerzialisierte API für den Zugriff an und erteilt nur durch einen Genehmigungsprozess einen Zugang. Das ist einerseits für die Entwicklung von Applikationen mit diesen NLP-Modellen bequem, da die Arbeit des Hostings und der Administration entfällt, andererseits ist die Eintrittsbarriere für Wettbewerber in diesen Markt so steil, dass im Wesentlichen die super-großen KI-Firmen dort teilnehmen: Google mit OpenAI, Microsoft mit Deepmind und Alibaba.
Die Konsequenzen dieser Monopolstellungen der führenden KI-Unternehmen sind wie bei jedem Monopol alternativlose Preismodelle und starre Geschäftspraktiken. Die Fähigkeiten der jetzigen Large Language Models wie GPT-3 und Megatron Turing NLG sind allerdings schon so beeindruckend, dass abzusehen ist, dass wahrscheinlich in 10 Jahren jedes Unternehmen für die unterschiedlichsten Anwendungen Zugriff auf die dann aktuellen Modelle braucht. Ein weiteres Problem ist, dass die Herkunft der Modelle aus dem amerikanischen oder chinesischen Raum einen großen Bias in die Modelle bringt, der sich einerseits klarerweise darin ausdrückt, dass Englisch oder Chinesisch die Sprache ist, mit der die Modelle am Besten funktionieren. Andererseits bringen die Trainingsdatensätze, die aus diesen Kulturbereichen stammen, eben kulturellen Tendenzen aus diesen Räumen mit, so dass abzusehen ist, dass andere Regionen der Welt unterrepräsentiert sind und weiter ins Hintertreffen geraten.
Was kann man tun?
Ich glaube es ist wichtig, die Entwicklung sorgfältig im Auge zu behalten und die Entwicklung von KI im europäischen Raum aktiver zu gestalten. Es ist jedenfalls eine größere Anstrengung notwendig, um langfristig eine Abhängigkeit von monopolisierten KI-Providern zu vermeiden. Denkbar ist vielleicht die Einbindung von nationalen Rechenzentren oder Forschungsverbünden, die vereint mit Unternehmen eigene Modelle trainieren und kommerzialisieren und ein Gegengewicht zu amerikanischen oder chinesischen Unternehmen bilden. Die nächsten 10 Jahre werden hier entscheidend sein.
1 s. hier in Abschnitt D sowie Compute-Kosten per GPU z.B. auf Google Cloud ca. 1USD/hour für eine NVIDIA V100
2 Rechenansatz: V100 = 7 TFLOPs = 7 10^12 / s, 3.14 10^23 Flops => 3.14 10^23/7×10^12 / 3600 = 10^7 Stunden = 10 Mio USD, Details der Rechnung sowie Recherche der Parameter hier.
3 s. auch hier zum Vergleich Grafik mit älteren Daten.
4 s. arxiv und Deepmind

