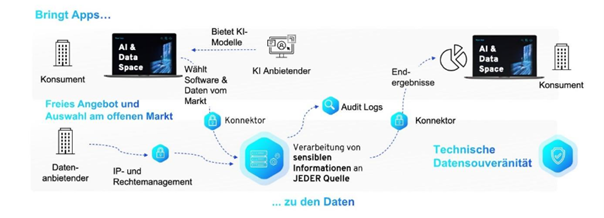
What do climate change, pandemic developments, and statistical risks have in common with the impact of digital transformation on an organization’s people? Short answer: There’s a well-documented human tendency to ignore or underestimate complex or abstract risks. And what does that have to do with organizational change management? I’ll explain it all in this blog post.
A classic example of statistical risks involves the impact of a lack of exercise, nicotine, or alcohol on the increasing risk of cardiovascular diseases. When organizations embark on a digital transformation, they face a staggering 70% risk of failure. So, where’s the connection?
In both scenarios, there are recognized and effective solutions to minimize these statistical risks. When it comes to digital transformation, that solution is the consistent application of organizational change management. It’s not enough to be perfectly set up technically and methodologically. The human factor – the people who are the target of the change – must also be a central focus.
What is organizational change management?
Organizational change management is a systematic approach. It actively manages the human side of change in an organization. This includes a range of processes, technologies, or strategies to support people through change and thus achieve the desired outcome.
“Managers assess that 69% of transformations fail due to insufficient change management.”
– Change Management Compass 2023, Porsche Consulting
Sounds familiar?
In my consulting practice, I often find that anecdotal or psycho-educational examples help people tap into their own experiences, sparking memories of similar situations. I often hear reactions like, “That’s exactly how it is for us too,” or “I can totally relate to a project like that.” That’s the exciting moment when things suddenly click, and connections are seen in a whole new light. Let me give you two examples:
1. Unclear direction
In one instance, the stated vision for a change program was simply: An 8% EBITA increase. However, employees in their day-to-day work couldn’t grasp how their efforts, directly or indirectly, contributed to this vision, which, let’s be honest, was more of a metric target.
They had no idea when or how this would be measured, what would happen next, or what it meant for them personally. They also didn’t know the consequences of either falling short or exceeding the target. Ultimately, this vision was a pretty ineffective way to provide direction.
It’s rarely just one missing piece. More often, it’s a combination of several underestimated or misunderstood situations and actions that, together, negatively impact the outcome far more significantly than any single one would appear to do.
2. Lack of Sponsorship
Understanding is fundamental to the willingness to support a change project. Employees must recognize that this change is important and urgent and that the consequences of ignoring this fact really must be avoided.
Part of this understanding is that the situation naturally commands adequate management attention. Someone needs to be at the helm, actively and with clear commitment, steering the ship around these critical shoals.
Here are the three most common misunderstandings about sponsorship I’ve encountered in projects:
- Top management views its sponsor role as something done exclusively behind closed doors, in steering committee meetings. Result: No one sees anyone actually steering.
- Responsibility for the change is delegated to a management level that lacks the necessary decision-making authority. Result: Someone is handed a tiny paddle and told to steer a supertanker.
- The entire topic of sponsorship simply hasn’t been formally clarified. Result: The steering wheel just spins wildly on its own.
Unclear visions and a lack of sponsorship are just two of the top drivers that can derail change initiatives.
Where skepticism and resistance brew
The human brain automatically fills in missing pieces. When intentions are opaque, information is scarce, and one’s own role in the changing landscape remains unclear, people instinctively fill those gaps with their own interpretations and explanations. These ideas spread like wildfire through the organization’s fastest communication channel – the rumor mill – where they’re vetted for plausibility. This includes things like ideas for better solutions, anxiety about no longer being seen as an expert, fear of losing the security that comes with familiar processes and tools, or the firm belief that “we can just keep doing things the way we always have.” Prominent themes are also appreciation, future prospects, and the fear of job loss.
To cut to the chase: we humans generally don’t like change. In fact, we often go to great lengths to preserve the status quo, or even to restore it if it’s been disrupted.
What role plays organizational change management?
At its core, organizational change management has three main goals:
- Accelerating adoption by boosting user acceptance and reducing resistance to new solutions or ways of working.
- Maximizing utilization by ensuring people consistently and effectively use new tools, processes, or systems, rather than reverting to old habits.
- Optimizing efficiency by empowering users to work productively with new solutions and unlock the full potential of the transformation.

Organizational change management: your path to success
Humans are a critical component of any digital transformation. Organizational Change Management is a critical success factor for any change project, ensuring that technological investments actually deliver their intended value.
And as I’m sure you’ll agree, there are indeed parallels between climate change, pandemic developments, and statistical risks, and the impact of digital transformation on an organization’s people: The more abstract and complex a danger or risk is, the more likely people are to underestimate or even ignore it. To minimize the significant risks posed by human factors in digital transformation, the consistent integration of organizational change management isn’t just helpful – it’s absolutely essential.