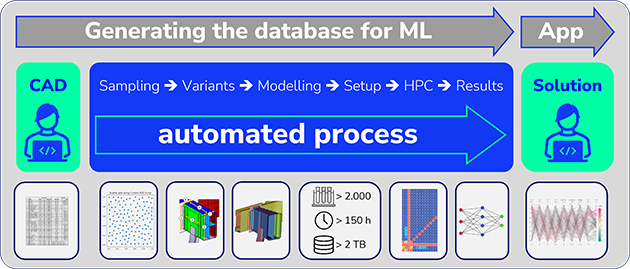
Artificial intelligence (AI) is a hot topic and increasingly important in product development. But how can this technology be effectively integrated into development projects? Together with our client Audi, we put it to the test and examined the potential and challenges of a machine learning (ML) application – a subset of AI – in a real project. For this purpose, we chose a crash management system (CMS). It is both simple enough to achieve a meaningful result and complicated enough to adequately test the general applicability of the ML method.
Expertise as the Key
ML can only be effectively utilized to the extent the underlying data foundation allows. Therefore, the expertise of the professionals involved plays a critical role. For example, design engineers enter their knowledge of manufacturing and spatial constraints, usable materials, and dependencies into the CAD model. Calculating engineers share their expertise on the simulation process, while data scientists assist with sampling and evaluation.
The creation of thousands of design and corresponding simulation models, as required for the use of Machine Learning (ML), presents a tremendous challenge without automation. The FCM CAT.CAE-Bridge, a specially developed plug-in for CATIA, enables seamless automation across all process steps. Additionally, it embeds all simulation-relevant information (material, properties, solver, and more) directly into the CAD model. The fully automatic translation into a simulation file is done via tools such as ANSA or Hypermesh.
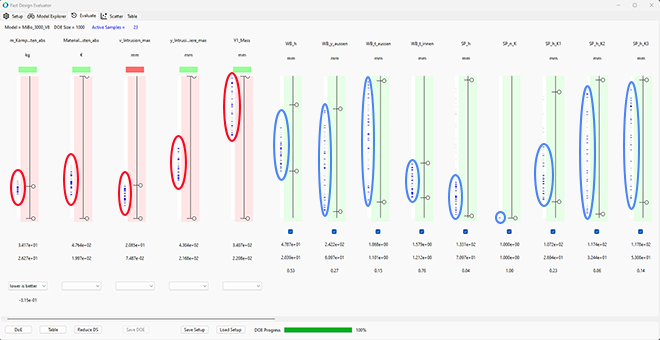
Our approach ensures that the relationship between the CAD model and the simulation model is fully preserved. The automated calculation and evaluation of the models based on specific results create an excellent data foundation for the ML process. The vectors of input parameters with corresponding result values form the basis for the ML approach—clear and comprehensive.
With the trained models and their known accuracy, parameter variations can be quickly tested, and the impact on behavior can be derived—literally within minutes. Once the optimal parameters are identified, they are automatically transferred to the CAD model and the design process can continue.
Conclusion
Our project demonstrated that ML is a valid method for design engineering. The combination of parametric CAD models, simulation, and machine learning provides an efficient approach to making design decisions quickly and accurately. The prerequisite for this is a robust database and the collaboration of the relevant experts on the model. The successful results from the Audi project demonstrate the potential of our data-based approach for product development.
Industry 4.0 promises more efficient and sustainable manufacturing processes through digitalization. The foundation for this is a seamless, automatic exchange of information between systems and products. This is where the Asset Administration Shell (AAS) comes into play.
An Asset Administration Shell is a vendor-independent standard for describing digital twins. Basically, it is the digital representation of an asset; either a physical product or a virtual object (e.g., documents or software).
The AAS defines the appearance of the asset in the digital world. It describes which information of a device is relevant for communication and how this information is presented. This means the AAS can provide all important data about the asset in a standardized and automated way.
Let us take a look at a practical application to understand the benefits of an AAS:
Use case: AAS as enabler for new services
As part of the ESCOM research project, CONTACT Software collaborates with GMN Paul Müller Industrie GmbH & Co. KG to implement AAS-based component services. The family-run company manufactures motor spindles which are installed by its customers as components in metalworking machine tools and then resold.
Before the project began, GMN had already developed a new sensor technology. It enables deep insights into the behavior of a spindle and provides information on overall operation of the spindle system. The company wants to use this data to offer new, product-related services:
Certified commissioning: Before GMN ships its spindles, the components are put through a defined test cycle on the company’s in-house test bench. GMN uses the data from this reference cycle to ensure that motor spindles are installed and commissioned correctly at the customer’s facility.
Predictive services: Using the IDEA-4S sensor microelectronics, customers shall be able to continuously record and analyze operating data that provide insights into the availability and operation of the spindles. If necessary, the data can be shared with GMN, for example, for problem analysis. This saves valuable time until the machine is back up and running. In the future, GMN will be able to offer smart predictive services like predictive maintenance.
About GMN Paul Müller Industrie GmbH
GMN Paul Müller Industrie GmbH & Co. KG is a family-owned mechanical engineering company based in Nuremberg, Germany. It produces high-precision ball bearings, machine spindles, freewheel clutches, non-contact seals, and electric drives that are used in various industries. The company manufactures most of these components individually for its customers on site and sells its products via a global sales network.
How do we realize the new services?
To provide such services, companies must be able to access and analyze the sensor data of their machines. Furthermore, machines (or their components) must be enabled to communicate independently with other assets and systems on the shopfloor.
For both tasks, GMN uses CONTACT Elements for IoT. The modular software not only helps the company to record, document and evaluate the reference and usage data of their spindles. It also includes functions that enable users to create, fill and manage the AAS for an asset.
Background
During the implementation of services based on spindle operating data, GMN benefits from the cooperation with a customer. This company installs the spindles in processing machines that GMN uses to manufacture its own products. As a result, GMN can gather the operating data in-house and use it to improve the next generation of spindles.
What role does the AAS play?
For the components to exchange information in a standardized form, an AAS must be created for the spindle at item and serial number level. This is also done using CONTACT Elements for IoT. The new services are mapped in a so-called AAS metamodel. It serves as a “link” to the service offers.
AAS and submodels
The AAS of an Industry 4.0 component consists of one or more submodels that each contain a structured set of characteristics. These submodels are defined by the Industrial Digital Twin Association (IDTA), an initiative in which 113 organizations from research, industry and software (including CONTACT Software) collaborate to define AAS standards. A list of all currently published submodels is available at https://industrialdigitaltwin.org/en/content-hub/submodels.
In CONTACT Elements for IoT, GMN can populate the AAS submodels with little effort. The platform includes a widget developed as a prototype during the research project. It provides an overview of which submodels currently exist for the asset and which are available but not yet created. Through the frontend, users can jump directly to the REST node server and upload or download submodels (in AAS/JSON format).
During the implementation of data-driven service offerings, GMN focuses on the submodels
Time Series Data (e.g., semantic information about time series data)
Digital Nameplate (e. g., information about the product, the manufacturer’s name, as well as product name and family),
Contact Information (standardized metadata of an asset) and
Carbon Footprint (information about the carbon footprint of an asset)
Filling the submodels is simple. This is demonstrated by the module Time Series Data. During the reference run of a motor spindle on the in-house test bench, the time series data is recorded by CONTACT Elements for IoT. The platform automatically transfers this data to the AAS submodel of the motor spindle being tested. At the same time, the platform creates a document for the reference run. This allows GMN to track its validity at any time and make it available to external stakeholders.
New services on the horizon
Using Asset Administration Shells allows GMN to realize its service ideas. This currently concerns the commissioning service and automated quality assurance services.
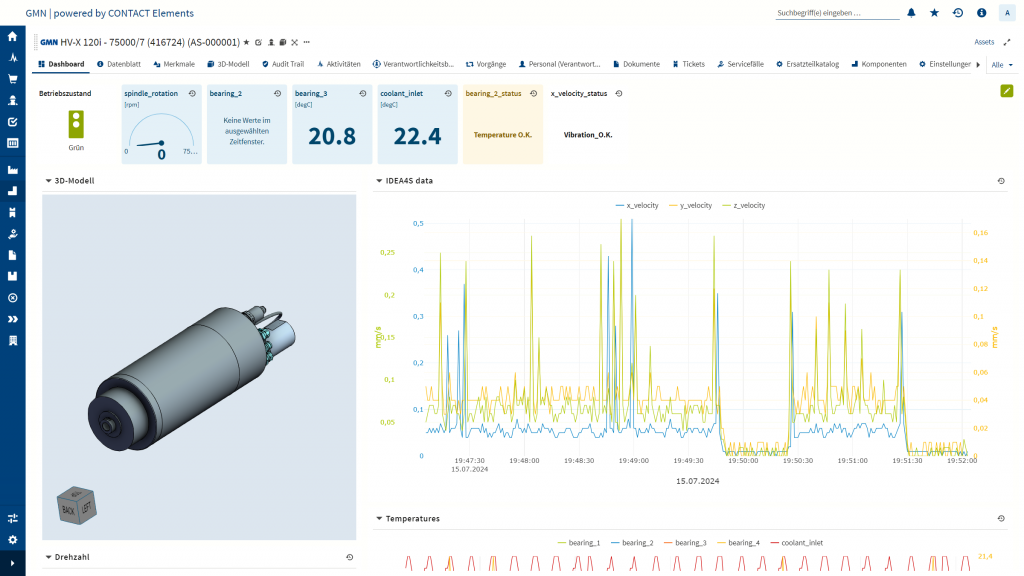
By analyzing the spindle data, the company can identify outliers in the operating data and make suitable recommendations for action. For example, different vibration velocities indicate an incorrect installation of the spindle in the machine or that time-varying processes are occurring. The analysis can also be used to provide insights about anomalies in operating behavior.
Dashboards in CONTACT Elements for IoT increase transparency. They provide GMN with all relevant information about the spindles on the test bench, from 3D models to status data. This overview is extremely valuable, particularly for quality management.
Summarized
Asset Administration Shells are vendor-independent standards for describing digital twins. They are among the most important levers for implementing new Industry 4.0 business models, as they enable communication between assets, systems, and organizations. The example of GMN demonstrates the practical benefits of the AAS. The company uses it to design new, product-related services based on information from the AAS of its products. GMN can successively improve these services by continuously analyzing operating data in CONTACT Elements for IoT.
In today’s digital age, we often question whether we can trust images, videos, or texts. Tracing the source of information is becoming more and more difficult. Generative AI accelerates the creation of content at an incredible pace. Images and audio files that once required a skilled artist can now be generated by AI models in a matter of seconds. Models like OpenAI’s Sora can even produce high-quality videos!
This technology offers both opportunities and risks. On the one hand, it speeds up creative processes, but on the other hand, it can be misused for malicious purposes, such as phishing attacks or creating deceptively real deepfake videos. So how can we ensure that the content shared online is genuine?
Digital watermarks: invisible protection for content
Digital watermarks are one solution that helps verify the origin of images, videos, or audio files. These patterns are invisible to the human eye but can be detected by algorithms even after minor changes, like compressing or cropping an image, and are difficult to remove. They are primarily used to protect copyright.
However, applying watermarks to text is way more difficult because text has less redundancy than pixels in images. A related method is to insert small but visible errors into the original content. Google Maps, for instance, uses this method with fictional streets – if these streets appear in a copy, it signals copyright infringement.
Digital signatures: security through cryptography
Digital signatures are based on asymmetric cryptography. This means that the content is signed with a private key that only the creator possesses. Others can verify the authenticity of the content using a public key. Even the smallest alteration to the content invalidates the signature, making it nearly impossible to forge. Digital signatures already ensure transparency in online communication, for example through the HTTPS protocol for secure browsing.
In a world where all digital content would be protected by signatures, the origin and authenticity of any piece of media could be easily verified. For example, you could confirm who took a photo, when, and where. An initiative pushing this forward is the Coalition for Content Provenance and Authenticity (C2PA), which is developing technical standards to apply digital signatures to media and document its origin. Unlike watermarks, signatures are not permanently embedded into the content itself and can be removed without altering the material. In an ideal scenario, everyone would use digital signatures – then, missing signatures would raise doubts about the trustworthiness of the content.
GenAI detectors: AI vs. AI
GenAI detectors provide another way to recognize generated content. AI models are algorithms that leave behind certain patterns, such as specific wording or sentence structures. Other AI models can detect these. Tools like GPTZero can already identify with high accuracy whether a text originates from a generative AI model like ChatGPT or Gemini. While these detectors are not perfect yet, they provide an initial indication.
What does this mean for users?
Of all the options, digital signatures offer the strongest protection because they work across all types of content and are based on cryptographic methods. It will be interesting to see if projects like C2PA can establish trusted standards. Still, different measures may be needed depending on the purpose of ensuring the trustworthiness of digital content. In addition to technological solutions, critical thinking remains one of the best tools for navigating the information age. The amount of available information is constantly growing; therefore, it is important to critically question, verify, and be aware of the capabilities of generative AI models.
For a more comprehensive article, check out the CONTACT Research Blog.