ESG-Konformität ist längst kein „Nice-to-have“ mehr. Sie ist Voraussetzung, um auf einem zunehmend nachhaltigkeitsbewussten Markt zu bestehen, Ressourcen und Kosten zu sparen – und immer strengere gesetzliche Anforderungen zu erfüllen. Regularien wie die von der Europäischen Kommission initiierte Corporate Sustainability Reporting Directive (CSRD) oder der Supply Chain Act fordern von Unternehmen, ESG-Daten transparent zu berichten. Während viele Organisationen dabei noch dokumentenzentriert arbeiten und mit Insellösungen kämpfen, entsteht an anderer Stelle ein strategischer Wettbewerbsvorteil: produktnahes ESG Reporting.
Was ist ESG Reporting?
Nachhaltiges Wirtschaften hat viele Facetten. Der ESG-Ansatz unterteilt es in drei zentrale Dimensionen:
• E = Environmental (Umwelt)
• S = Social (Soziales)
• G = Governance (Unternehmensführung)
In einem ESG Report berichten Unternehmen über alle drei Bereiche. Dazu gehören Daten wie CO2-Bilanzen, Energieverbräuche der Produktion und des Unternehmens sowie beispielsweise Informationen zur Förderung von Biodiversität und Vermeidung von Abfällen. Auch Themen wie die Einhaltung von fairen Arbeitsbedingungen und Menschenrechten, Sicherstellung von Diversität, Risikomanagement und Compliance müssen berücksichtigt werden.
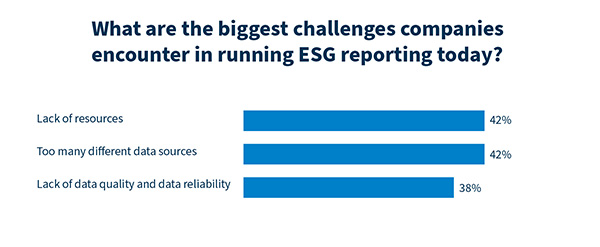
Datenmanagement ist die Königsdisziplin im ESG Reporting
Diese Daten – insbesondere umweltrelevante KPIs – liegen häufig in verschiedenen Quellen verstreut: in eigenen IT-Tools, externen Umweltdatenbanken oder Systemen von Zulieferern und Partnern. In der Praxis läuft die Erstellung eines ESG-Berichts deshalb für viele Unternehmen auf eine zentrale Frage hinaus: Wie lassen sich belastbare ESG-Daten aus verschiedenen Quellen entlang der gesamten Wertschöpfungskette erfassen und auswerten?
Ein Schlüssel liegt darin, das ESG Reporting in der Produktentwicklung – also im PLM-System – zu verankern. Hier liegen entscheidende Daten entlang des gesamten Produktlebenszyklus ab: Informationen über das Produktportfolio, verwendete Materialien und deren Sourcing, Emissionen aus Herstellung und Lieferkette – aber auch zu späteren Lebensphasen wie Nutzung, Entsorgung und Recycling. Durch diese systematisierte und nachvollziehbare Datenbasis bildet ein PLM-System die ideale Grundlage für eine präzise, transparente und strategisch nutzbare Nachhaltigkeitsbewertung.
Produktnahe Single Source of Truth als Enabler
Eine offene Integrationsplattform wie CONTACT Elements bietet für die ESG-Berichterstattung einen weiteren entscheidenden Vorteil: Sie bindet Informationen aus verschiedenen internen und externen Quellen nahtlos ein. Über APIs tauscht sie Daten mit Drittsystemen wie ERP-Tools aus. Informationen aus der Lieferkette lassen sich über standardisierte Austauschformate wie die Verwaltungsschale (Asset Administration Shell) oder Datenökosysteme (wie Pontus-X oder Catena-X) integrieren. So wird die Plattform zur Single Source of Truth für ein unternehmensweites ESG Reporting aus einer Hand.
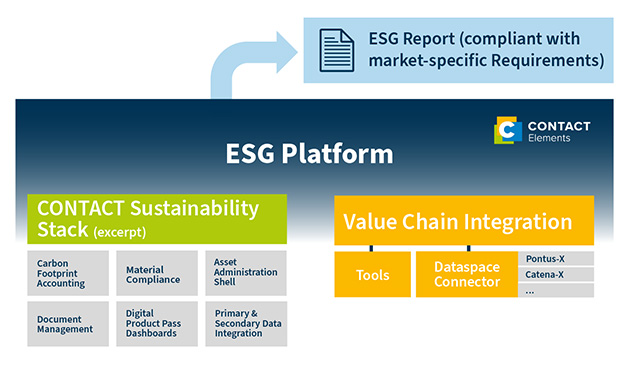
Idealerweise haben solche Lösungen direkt Funktionen an Bord, um die Daten zu bewerten und zu analysieren. CONTACT Elements beispielsweise nutzt KI-Methoden, um die Datenqualität zu evaluieren. Leistungsstarke Module, etwa zur Berechnung des Product Carbon Footprint, erstellen daraus im nächsten Schritt einen belastbaren ESG-Bericht. So entsteht ein durchgängiges, auditfähiges Reporting, das alle marktspezifischen Anforderungen erfüllt.
Vom ESG Reporting zur Nachhaltigkeitsstrategie
Wer heute auf produktnahe, integrierte Lösungen wie CONTACT Elements setzt, meistert nicht nur das „Pflichtprojekt“ ESG Reporting, sondern kann Nachhaltigkeit strategisch im Unternehmen verankern. Beispielsweise lassen sich ESG-Daten in CONTACT Elements direkt mit Produktstrukturen und Entwicklungsprozessen verknüpfen. Entwickler*innen können dadurch frühzeitig Aussagen zu entstehenden CO2-Emissionen innerhalb des Produktportfolios oder in konkreten Fertigungsverfahren und -prozessen treffen und diese zielgerichtet optimieren.
Das Resultat: nachhaltige Innovationen, attraktivere Produkte, effizientere Prozesse und niedrigere Kosten. Die Grundlage dafür ist in jedem Fall eine Software-Plattform wie CONTACT Elements: offen, skalierbar und mit leistungsstarken Fachanwendungen.
Erfahren Sie in diesem Beitrag des Beratungsunternehmens CIMdata, wie Unternehmen Nachhaltigkeit systematisch im PLM verankern, um ihre Umweltauswirkungen entlang des gesamten Produktlebenszyklus zu reduzieren.