
Was ist eine Verwaltungsschale?
Industrie 4.0 verspricht effizientere und nachhaltigere Fertigungsprozesse via Digitalisierung. Die Grundlage hierfür entsteht durch den reibungslosen, automatischen Austausch von Informationen zwischen Anlagen und Produkten. Hier kommt die Verwaltungsschale (VWS; englisch: Asset Administration Shell) ins Spiel.
Eine Verwaltungsschale ist ein anbieterunabhängiger Standard für die Beschreibung Digitaler Zwillinge. Im Grunde ist sie das digitale Abbild eines Assets; entweder eines physischen Produkts oder eines virtuellen Gegenstands (z. B. Dokumente oder Software).
Die VWS definiert das Erscheinungsbild des Assets in der digitalen Welt. Sie beschreibt, welche Informationen eines Gerätes für die Kommunikation relevant sind und wie diese Informationen dargestellt werden. Die VWS eines Gegenstands kann damit alle wichtigen Daten über das Asset standardisiert und automatisiert bereitstellen.
Um zu verstehen, welchen Mehrwert eine VWS der Industrie bietet, hilft ein Blick in die Praxis.
Praxisbeispiel: VWS als Basis für neue Dienstleistungen
Im Rahmen des Forschungsprojekts ESCOM arbeitet CONTACT Software mit der GMN Paul Müller Industrie GmbH & Co. KG an der Umsetzung VWS-basierter Komponenten-Services. Das familiengeführte Unternehmen produziert Motorspindeln, die von seinen Kunden als Komponenten in Werkzeugmaschinen für die Metallbearbeitung eingebaut und anschließend weiterverkauft werden.
Bereits vor Beginn des Projektes hatte GMN eine neue Sensortechnologie entwickelt. Sie ermöglicht tiefe Einblicke in das Verhalten der Spindel und gewährt Aussagen zum ganzheitlichen Betrieb des Spindelsystems. Diese Informationen will die Firma nutzen, um neue, produktbegleitende Dienstleistungen anzubieten:
- Zertifizierte Inbetriebnahme: Bevor GMN seine Spindeln ausliefert, werden die Komponenten auf dem hauseigenen Prüfstand einem festgelegten Prüfzyklus unterzogen. Mit den Daten aus diesem Referenzzyklus will das Unternehmen sicherstellen, dass Motorspindeln im Kundenunternehmen korrekt verbaut und in Betrieb genommen werden.
- Prediktive Services: Einsatzdaten, die Rückschlüsse zur Verfügbarkeit und zum Betrieb der Spindeln erlauben, sollen Kunden mit der sensorischen Mikroelektronik IDEA-4S kontinuierlich erfassen und analysieren können. Im Bedarfsfall können die Daten gemeinsam mit GMN genutzt werden, zum Beispiel für Problemanalysen. Dies spart wertvolle Zeit bis zur Wiederinbetriebnahme der Bearbeitungsmaschine. Perspektivisch kann das Unternehmen vorausschauende Service-Angebote wie Predictive Maintenance realisieren.
Über die GMN Paul Müller Industrie GmbH
Die GMN Paul Müller Industrie GmbH ist ein familiengeführtes Maschinenbauunternehmen mit Sitz in Nürnberg. Es produziert Hochpräzisionskugellager, Maschinenspindeln, Freiläufe, berührungslose Dichtungen sowie elektrische Antriebe, die in zahlreichen Industrien zum Einsatz kommen. Einen Großteil dieser Komponenten fertigt die Firma individuell für ihre Kunden am Standort und vertreibt seine Produkte über ein weltweites Vertriebsnetzwerk.
Wie werden die neuen Angebote umgesetzt?
Für solche Services müssen Unternehmen auf die Sensordaten ihrer Maschinen zugreifen und diese analysieren können. Zugleich gilt es, Maschinen (bzw. deren Komponenten) zu befähigen, selbstständig mit anderen Assets und Systemen rund um den Shopfloor zu kommunizieren. Für beide Aufgaben nutzt GMN die Plattform CONTACT Elements for IoT. Die modular aufgebaute Software hilft dem Unternehmen nicht nur, die Referenz- und Einsatzdaten der Spindeln zu erfassen, zu dokumentieren und auszuwerten. Sie enthält auch Funktionen, mit denen User die VWS für ein Asset anlegen, befüllen und verwalten können.
Hintergrund
Bei der Realisierung der Services, die auf Betriebsdaten der Spindel basieren, profitiert GMN von der Zusammenarbeit mit einem Kunden. Dieser verbaut die Spindeln in Bearbeitungsmaschinen, die GMN zur Herstellung eigener Produkte einsetzt. Daher kann GMN die Betriebsdaten in-house gewinnen und zur Verbesserung der nächsten Spindelgeneration verwenden.
Welche Rolle spielt die Verwaltungsschale?
Damit die Komponenten Informationen in standardisierter Form austauschen können, muss für die Spindel auf Artikel- und Seriennummernebene eine AAS angelegt werden. Auch dies geschieht in CONTACT Elements for IoT. Die neuen Services werden darin in einem sogenannten VWS-Metamodell abgebildet. Es dient als „Absprungpunkt“ zu den Service-Angeboten.
VWS und Teilmodelle
Die VWS einer Industrie 4.0-Komponente besteht aus einem oder mehreren Teilmodellen, die jeweils eine strukturierte Menge an Merkmalen enthalten. Sie werden von der Industrial Digital Twin Association (IDTA) festgelegt, einem Verein, in dem 113 Organisationen aus den Bereichen Forschung, Industrie und Software (u. a. CONTACT Software) an der Definition von VWS zusammenarbeiten. Eine Liste mit allen derzeit verfügbaren Teilmodellen finden Sie unter https://industrialdigitaltwin.org/content-hub/teilmodelle.
Die Teilmodelle der VWS kann GMN in CONTACT Elements for IoT mit wenig Aufwand selbst befüllen. Die Plattform beinhaltet ein Widget, das im Rahmen des Forschungsprojekts als Prototyp entwickelt wurde. Es zeigt Usern an, welche Teilmodelle derzeit beim Asset vorhanden und welche verfügbar, aber noch nicht angelegt sind. Über das Frontend können User direkt auf den REST-Knoten springen und Teilmodelle hoch- bzw. herunterladen (im VWS-/JSON-Format).
Bei der Umsetzung der datenbasierten Service-Angebote konzentriert sich GMN auf die Teilmodelle
- Time Series Data (u. a. semantische Informationen über Zeitreihendaten)
- Typenschild (u. a. Informationen zum Produkt, dem Namen des Herstellers sowie der Produktbezeichnung und -familie),
- Kontaktinformationen (standardisierte Metadaten einer Maschine/Anlage) sowie
- Carbon Footprint (Informationen zum Carbon Footprint einer Maschine/Anlage)
Die Befüllung der Teilmodelle ist simpel. Das zeigt sich im Kontext von GMN am Modul Time Series Data. Während der Referenzfahrt einer Motorspindel auf dem internen Prüfstand werden die Zeitreihendaten von CONTACT Elements for IoT aufgezeichnet und automatisch in das Teilmodell der VWS der gerade geprüften Motorspindel übertragen. Zugleich legt die Plattform ein Dokument zur Referenzfahrt an. Dadurch kann GMN deren Gültigkeit jederzeit tracken und für externe Stakeholder bereitstellen.
Neue Services nehmen Gestalt an
Der Einsatz von Verwaltungsschalen erlaubt es GMN, seine Service-Ideen zu realisieren. Das betrifft aktuell den Inbetriebnahme-Service und die automatisierten Services zur Qualitätssicherung.
Durch die Analyse der Spindeldaten kann das Unternehmen Ausreißer in den Einsatzdaten erkennen und darauf aufbauend Handlungsempfehlungen geben. Unterschiedliche Schwinggeschwindigkeiten deuten beispielsweise darauf hin, dass die Spindel in der Maschine falsch verbaut wurde oder zeitlich veränderliche Vorgänge stattfinden. Genauso lassen sich anhand der Analyse Aussagen über Anomalien im Betriebsverhalten treffen.
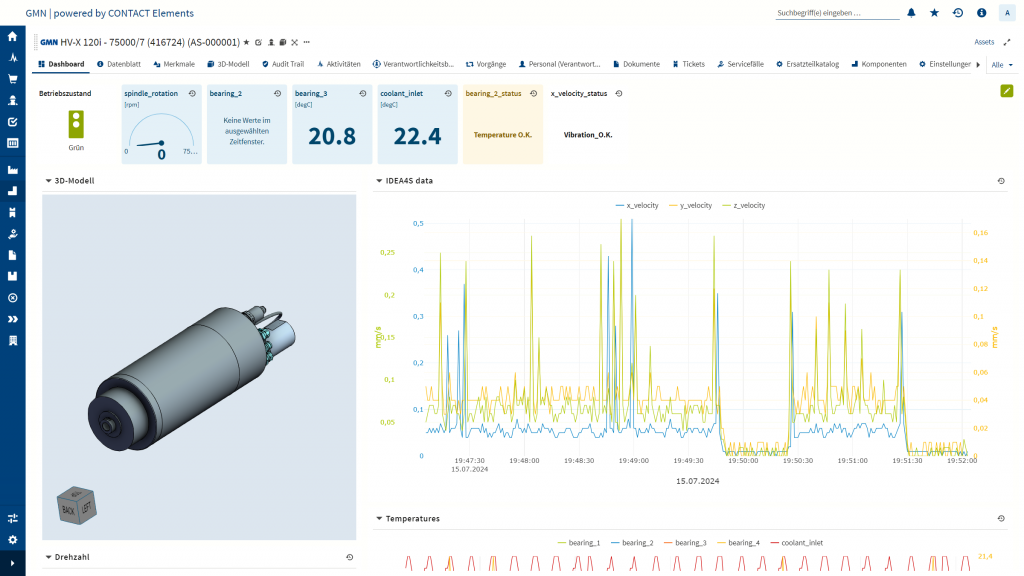
Die Transparenz, die auf diesem Weg entsteht, wird in CONTACT Elements for IoT mithilfe von Dashboards erhöht. GMN sieht darin alle relevanten Informationen zu den auf dem Prüfstand befindlichen Spindeln, von 3D-Modellen bis hin zu Zustandsdaten. Diese Übersicht ist nicht zuletzt für das Qualitätsmanagement von hohem Wert.
Zusammengefasst
Verwaltungsschalen sind anbieterunabhängige Standards, mit denen Unternehmen Digitale Zwillinge beschreiben. Sie zählen zu den wichtigsten Hebeln für die Umsetzung neuer Industrie-4.0-Geschäftsmodelle, denn sie ermöglichen die Kommunikation zwischen Assets, Systemen und Organisationen.
Wie der Einsatz von Verwaltungsschalen in der Praxis funktioniert, zeigt das Beispiel GMN. Die Firma konzipiert damit neue, produktbegleitende Dienstleistungen, die auf den Informationen der VWS ihrer Produkte basieren. Diese Angebote kann GMN durch die fortwährende Analyse von Einsatzdaten in CONTACT Elements for IoT sukzessive verbessern.


