Sie stehen vor der Entscheidung Ihr Product Lifecycle Management (PLM) auf den neuesten Stand bringen oder überhaupt erst einzuführen. Die Vorteile sind klar: effizientere Prozesse, schnellere Markteinführung, bessere Zusammenarbeit. Doch sobald die Funktionslisten und Anwendungsfälle besprochen sind, rückt eine andere wichtige Frage in den Mittelpunkt: Was kostet das eigentlich – und welche Option ist wirklich die günstigere auf lange Sicht?
Die Wahl zwischen Cloud PLM und der klassischen On-Premises-Lösung ist oft ein Ritt zwischen der initialen Investitionsbereitschaft und flexiblen, laufenden Betriebskosten. In diesem Beitrag werfen wir einen Blick auf die Kosten von Cloud PLM vs. On-Premises PLM.
Die traditionelle Variante: On-Premises PLM
Wenn Sie sich für ein On-Premises PLM-System entscheiden, erwerben und betreiben Sie die Software in Ihrer eigenen IT-Infrastruktur. Dies bedeutet eine hohe Anfangsinvestition, aber auch volle Kontrolle.
Anschaffungskosten:
- Software-Lizenzen: Dies ist oft der größte Posten. Sie kaufen Dauerlizenzen, die Ihnen das unbegrenzte Nutzungsrecht an der Software gewähren. Die Kosten variieren je nach Anbieter, Funktionsumfang und Anzahl der Benutzer*innen.
- Hardware-Infrastruktur: Sie benötigen leistungsstarke Server, Speichersysteme, Netzwerkkomponenten und Back-up-Lösungen. Diese müssen den Anforderungen des PLM-Systems gerecht werden und für zukünftiges Wachstum skalierbar sein.
- Infrastrukturkosten: Ein geeigneter Serverraum (Klimatisierung, Stromversorgung, etc.), Firewalls etc. sind unerlässlich.
- Implementierung und Anpassung: Die Installation, Konfiguration und Datenmigration aus Altsystemen sowie die Anpassung an spezifische Unternehmensprozesse erfordern oft externe Beratungsleistungen und interne Ressourcen.
- Schulungen: Umfassende Schulungen für Administrator*innen und Endbenutzer*innen sind notwendig, um das System optimal zu nutzen.
Laufende Kosten:
- Wartungs- und Supportverträge: Die meisten Softwareanbieter verlangen jährliche Gebühren für Software-Updates, Patches und technischen Support. Diese liegen typischerweise bei 15-25 % des ursprünglichen Lizenzpreises pro Jahr.
- IT-Personal: Sie benötigen eigene IT-Spezialist*innen für die Systemwartung, Fehlerbehebung, Sicherheit, Backups und Performance-Optimierung.
- Hardware-Wartung und Austausch: Server und Speicher müssen regelmäßig gewartet und nach einigen Jahren ersetzt werden (Abschreibung, Neuanschaffung).
- Energiekosten: Der Betrieb der Server und der Klimaanlage verursacht laufende Stromkosten.
- Sicherheitsmaßnahmen: Lizenzen für Antivirensoftware, Firewalls und regelmäßige Penetrationstests sind notwendig, um die Datensicherheit zu gewährleisten.
- Upgrades: Größere Versions-Upgrades können den Umfang einer Neuimplementierung erreichen, da sie oft Anpassungen, intensive Tests und erneute Schulungen erfordern.
Die flexible Alternative: Cloud PLM
Beim Cloud PLM (oft als Software-as-a-Service, SaaS, angeboten) mieten Sie die Software und die Infrastruktur eines Drittanbieters. Das bedeutet in der Regel geringere Anfangsinvestitionen.
Anschaffungskosten:
- Einrichtungsgebühren (optional): Einige Anbieter erheben eine einmalige Gebühr für die Einrichtung des Kontos oder die Erstkonfiguration.
- Implementierung und Anpassung: Auch hier sind Dienstleistungen für die Konfiguration, Datenmigration und spezifische Prozessanpassungen erforderlich. Diese können jedoch meist weniger umfangreich sein, da die Basisinfrastruktur bereits vorhanden ist und die Cloud-Lösungen oft standardisiert sind.
- Integrationen: Die Anbindung an bestehende On-Premises-Systeme kann Integrationsprojekte erfordern, die mit Kosten verbunden sind.
- Schulungen: Schulungen für Anwender*innen und Administrator*innen sind ebenfalls notwendig, können aber durch intuitive Benutzeroberflächen und Online-Ressourcen oft effizienter gestaltet werden.
Laufende Kosten:
- Abonnementgebühren: Dies ist der Hauptkostenfaktor. Sie zahlen eine monatliche oder jährliche Gebühr pro Benutzer*in, oft gestaffelt nach Funktionsumfang. Diese Gebühren umfassen die Softwarenutzung, Infrastruktur, Wartung, Updates und den grundlegenden Support.
- Skalierung: Das Hinzufügen oder Entfernen von Benutzer*innen oder Speicherplatz ist in der Regel flexibel und wird direkt in den Abonnementgebühren widergespiegelt.
- Premium-Support/Zusatzleistungen: Für erweiterten Support, spezielle Add-Ons oder zusätzliche Speicherplatz können extra Gebühren anfallen.
- Anpassungen/Integrationen: Laufende Anpassungen oder die Entwicklung neuer Integrationen können zusätzliche Dienstleistungsgebühren verursachen.
- Internetzugang: Ein zuverlässiger und ausreichend schneller Internetzugang ist essenziell und sollte in der Kalkulation berücksichtigt werden, auch wenn er oft schon vorhanden ist.
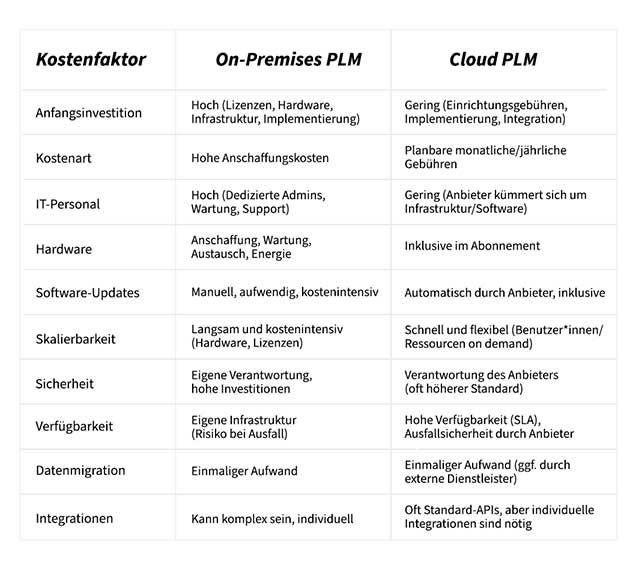
Der direkte Kosten Vergleich:
Um eine fundierte Entscheidung zu treffen, ist es unerlässlich, die Gesamtkosten über einen Zeitraum von 5 bis 10 Jahren zu betrachten.
Fazit:
Die optimale Lösung bei der Wahl zwischen Cloud PLM und On-Premises PLM hängt stark von den individuellen Gegebenheiten Ihres Unternehmens ab:
- Für kleine und mittelständische Unternehmen (KMU), die schnell starten, IT-Ressourcen schonen und von geringeren Anfangsinvestitionen profitieren möchten, ist Cloud PLM oft die wirtschaftlichere Wahl. Die planbaren monatlichen Kosten und die automatische Wartung entlasten die interne IT erheblich.
Wenn Sie die Vorteile von Cloud PLM in der Praxis erleben möchten, bietet CONTACT Softwares Cloud PLM-System eine flexible und skalierbare Lösung. Besonders interessant: Sie können die Software kostenlos testen und sich selbst ein Bild davon machen, wie modernes Product Lifecycle Management in der Cloud Ihre Entwicklungsprozesse effizienter gestaltet.
- Für große Unternehmen oder solche mit sehr spezifischen, komplexen Anforderungen, die maximale Kontrolle über ihre Daten und Systeme wünschen und über die notwendigen IT-Ressourcen verfügen, kann On-Premises PLM weiterhin die bevorzugte Option sein. Die hohen Anfangsinvestitionen relativieren sich oft über längere Nutzungszeiträume.