
Mit dem Aufstieg moderner KI-Systeme hört man auch immer häufiger Sätze wie „Text wird in ein Embedding umgewandelt…“, gerade beim Einsatz großer Sprachmodelle (engl. Large Language Models, LLMs). Embeddings sind aber nicht nur auf Texte reduziert, sondern Vektordarstellungen für jede Art von Daten.
In den letzten Jahren hat sich Deep Learning stark weiterentwickelt, insbesondere durch das Trainieren großer Modelle auf umfangreichen Datensätzen. Diese Modelle erzeugen universell einsetzbare Embeddings, die in vielen Domänen nützlich sind. Da die meisten Entwickler nicht die Ressourcen für eigenes Training haben, nutzen sie vortrainierte Modelle.
Viele KI-Systeme basieren auf dem folgenden Schema:
Input → API (zu großem Deep-Learning-Modell) → Embeddings → Embeddings verarbeiten → Output
In diesem Blogeintrag tauchen wir daher tiefer in diesen zentralen Bestandteil von KI-Systemen ein.
Was sind Embeddings?
Einfach gesagt ist ein Embedding eine Art digitale Zusammenfassung: eine Zahlenfolge, die Eigenschaften eines Objekts – sei es Text, Bild oder Audio – beschreibt. Die Embeddings von ähnlichen Objekten liegen im Raum nah beieinander.
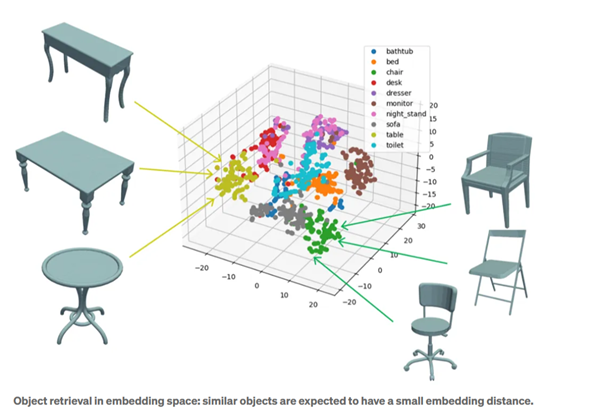
Technisch ausgedrückt sind Embeddings Vektordarstellungen von Daten. Sie basieren auf einer Abbildung (Embedder, Encoder), die wie ein Übersetzer funktioniert. Moderne Embeddings sind häufig tiefe neuronale Netze und reduzieren komplexe Daten auf eine niedrigere Dimension. Allerdings gehen durch die Komprimierung teilweise Informationen verloren. Aus einem Embedding lässt sich daher nicht immer der genaue Input rekonstruieren.
Wie funktionieren Embeddings?
Embeddings sind keine neue Erfindung, haben sich durch Deep Learning aber wesentlich verbessert. Nutzer*innen erstellen sie manuell oder automatisch durch maschinelles Lernen. Frühe Methoden wie Bag-of-Words oder One-Hot-Encoding sind einfache Varianten, bei denen Wörter gezählt oder als Binärvektoren dargestellt werden.
Heute übernehmen neuronale Netze diese Arbeit. Modelle wie Word2Vec oder GloVe lernen die Bedeutung und Beziehungen zwischen Wörtern automatisch. In der Bildverarbeitung finden Deep-Learning-Modelle Schlüsselpunkte und extrahieren Merkmale.
Warum sind Embeddings nützlich?
Weil sich nahezu jede Art von Daten mit Embeddings darstellen lässt: Text, Bilder, Audio, Videos, Graphen usw. Im niedrigdimensionalen Vektorraum lassen sich Aufgaben wie Ähnlichkeitssuche oder Klassifikation einfacher lösen.
Wenn man zum Beispiel in einem Text wissen möchte, welches von drei Wörtern nicht zu den anderen passt, ermöglichen Embeddings es diese Wörter als Vektoren darzustellen, zu vergleichen und so die „Ausreißer“ zu erkennen. Außerdem verknüpfen Embeddings unterschiedliche Formate. Eine Textanfrage findet zum Beispiel auch Bilder und Videos.
Für viele Aufgaben müssen Embeddings nicht selbst erstellt werden. Es gibt zahlreiche vortrainierte Modelle, die direkt zur Verfügung stehen – von ChatGPT bis hin zu Bildmodellen wie ResNet. Für spezifische Nischenbereiche oder Aufgaben können diese Modelle entsprechend angepasst werden.
Kleine Zahlen, große Wirkung
Embeddings sind zu einem der Schlagwörter für den Aufbau von KI-Systemen geworden. Die Idee ist einfach: komplexe Daten in handliche Vektoren zu verwandeln, mit denen sich unter anderem Unterschiede und Ähnlichkeiten erkennen lassen. Dabei hat man die Wahl zwischen vortrainierten Embeddings oder der Entwicklung eigener Modelle. Embeddings ermöglichen es, Daten verschiedener Modalitäten (Text, Bilder, Videos, Audio usw.) im selben Vektorraum zu repräsentieren und sind so ein unverzichtbares Werkzeug im Bereich der KI.
Einen ausführlichen Beitrag zum Thema finden Sie auch auf dem CONTACT Research Blog.